Synapse stuff
This document outlines the tasks completed or attempted while working on Synapse - effectively akin to a research journal but as part of a production-intended project instead of a more specific study.
It was originally in a google doc, but got moved here because setting up file uploads with a half-configured mediawiki install seemed easier than figuring out a pile of unlabelled buttons on said google doc.
Task 1 - usable existing products
Different ways to collaboratively edit a document - generally you do want a platform for that instead of just emailing a thing around or whatever...
Wikis
- Shared document/page - open for editing, save changes, folks see changes
- Issues with edit conflicting
- Generally cannot easily have multiple copies of the same thing
Available potentially extendable products:
Real-time editors
Probably want a real-time editor. Going with Google Drive for now for ease of setup. Will need something that can be integrated into the main app
- Edit live - automatically saves as one goes
- Folks can see each other type
- Danger of messing things up - change mind about changes, need to manually reload previous save; not possible if others editing at the same time
Available potentially extendable products:
- Etherpad
- Open source, free to use, has APIs, kind of messy front-end, would probably work with hacking.
- Google Drive
- Simple solution: link to a drive document, go there and use that
- Integratable? Check terms of use, APIs, might work perfectly.
- BeWeeVee
- Specifically created for integrating into other things, uses .Net/js, free for academic/NC use - would probably work fairly well without too much trouble.
Task 2 - MVP demo
Work on script, record an audio...
Fiddled with it, and came up with something which fortunately wasn't used.
Task 3 - questions
How can we get people signed up for our private beta?
How can we run A/B testing for our demo?
Ways to reach people to bring them to the landing launchy page
- Search engine results - SEO is crap/nonexistent, so only was is through ads on results.
- Ads on sites through some campaign manager
- Social networking - linkedin, facebook, twitter
- Mail spam to potential users - cu mailing list, perhaps, others
- Word of mouth/getting people to share it themselves - reddit, clear share button on page, etc
Would probably want to do all of those, if possible. Emphasis on the last three because they cost less, and emphasis on the first one because it’s likely to find people the same way they’d be finding the product itself later once it does have a proper web presense, so if it would work later, it should work now.
How will this relate to google hangout? (commonly used by folks meeting with remote colleagues)
A/B testing:
Set up 1-2 more launch pages, Houman will make the actual landing thing in js, which should serve to scare off anyone like me, which is a good demographic to keep away from such things.
Prototypes

Simple centered video

Series of steps leading to video

Massive pile of crankiness dumped on a page



Prototype components:
- Logo/wordmark and slogan
- About
- (Feature highlight - shared notes, shared discussion, easy access later to organise archives)
- Video(s)
- Sign up for private beta
- (Toggle between business/school)
General flow of page:
- This thing!
- You want this thing!/You want this thing because!
- Now that you're interested, watch this for more info!
- Now sign up for this thing!
If that doesn't work it's hopeless. Or something is wrong, at any rate.
Task 4 - prototypes
Mockups/prototypes to give folks a feel for the product...
Wireframes
General site layouts for academic version.
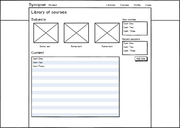
Library of courses/projects/whatever
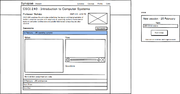
View of a specific course with session open
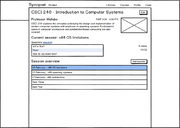
Instructor view of course

Notes page and recording app


_wireframe.png)

Mockups
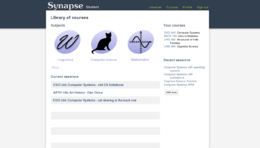
Library of courses/projects/whatever
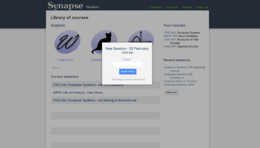
Creating a new course session from the library
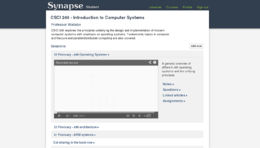
View of a specific course with session open
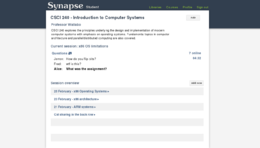
Instructor view of course
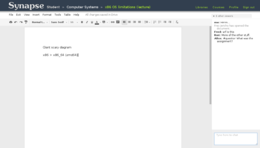
Notes page



_mockup.png)

Task 5 - feasibility stuff
- How to parse a google doc (API results, etc, what would be pulled out)?
- Something about how to match up snippets of audio from different sources - algorithms, established methods, possible products, etc.
Parsing google doc
From developers.google.com:
Download the content as described (probably as plain text since we're unlikely to care about images, text format, etc for this).
To parse, regex would probably be more than sufficient:
- Find sentences ending with questions
- Find hashtags
- Etc
Need to have a background process on the server or something to update - use the changes feed; check new changes(?) and reparse as needed.
Matching audio clips
The aim is to find overlap between multiple different recordings in order to combine disjoint recordings of the same meeting into a single, higher-quality file.
We probably want to match the acoustic fingerprints of audio files as the first part of the process. Normally this sort of technology tends to be used for identifying music, but applications developed for that may work for this as well. In essence a fingerprint is a simplification of an audio file that focusses the perceptual characteristics (what a person would hear), and from this a basic comparison allowing for a certain range of variance between file fingerprints should serve our needs.
An existing open source solution such as Echoprint or AcoustID would probably be ideal if they would work.
The problem is how to figure out what, if any such option, would actually work.
- Recordings from different devices and places will contain considerably more variance and differing noise than reencodings of a song.
- Depending on how an implementation handles partial recordings, these may or may not even work to find overlap in the recordings.
Alternately generating our own 'fingerprints' for each snippet and then running them through a sloppy comparison possibly using the same methods as to generate the fingerprints in the first place - are they similar enough? - to match them up might be another, potentially more robust, option.
A paperly overview of some of the technology can be found here: Fingerprint-Cano.pdf